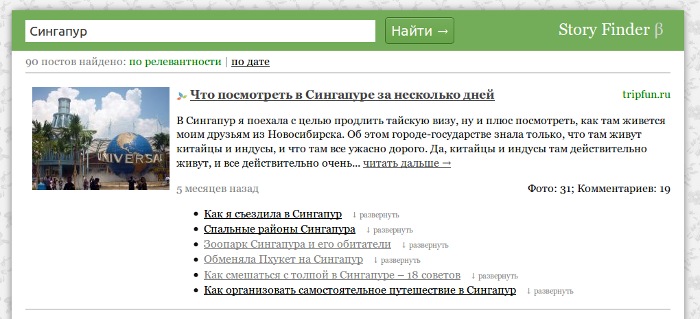
Что ж, пришло время поподробнее рассказать про мой новый проект, поисковик по тревел блогам, и как я его делал. Первые строчки кода я написал почти два месяца назад, а публичный бета-тест начался три недели назад. Я хотел написать обо всём в следующем посте итогов, но слишком уж много информации скопилось 🙂 Поисковиком его называть пока рано, это скорее поиск по тегам — гео.названиям, вбиваешь город или место — и тебе список постов от путешественников, побывавших там. Можете попробовать — StoryFinder.ru
Как мне вообще пришла в голову такая идея? Ну, как часто путешествующий, я читаю посты других людей о месте, куда направляюсь. А где их искать? Гугл и Яндекс выдают сплошняком нерелевантную информацию (отели, погода, рерайт статей), поиск по блогам полон всякими твиттами и форумами. Есть одна подборка на основе Google Custom Search, но она не полная, и не очень наглядная (но раньше пользовался в основном им). Когда-то давно я хотел сам вручную собирать подобные анонсы, когда хотел писать статьи по местам, но это слишком глупая и ресурсоемкая задача. Лучше её автоматизировать!)
Что я и сделал. Я не стал создавать полностью универсального паука-краулера, это слишком сложно, да и не нужно. Список всех страниц? Sitemap.xml, который парсится двумя строчками (или atom-фид всех постов блога в блогспоте). Текст поста? Тут пришлось повозится, но использовав Simple HTML DOM Parser и стандартизированную верстку WordPress/Blogspot, я довольно быстро стал получать нужную мне информацию — сам пост, заголовок, число фотографий (для тревел-блогов это очень важный параметр), число комментариев (как показатель качества) и прочие мелочи. С каждым новым добавляемым блогом приходилось дописывать всё новые и новые правила в парсер, сейчас для одного только определения основного текста используется 27 классов/идентификаторов (пробуем например div.entrypost, если его нет — div.post, и т.д.). Зато сейчас для новых блогов уже почти не приходится ничего дописывать, всё сразу парсится правильно (для большинства вордпресс тем). Правда, тут вступают в игру блоги на Joomla, Ucoz, TextPattern и прочих, корявая невалидная верстка, лимиты для загрузки страниц (укоз) и прочее прочее)
А что сам поиск? Конечно, можно было бы использовать готовый движок, типа Sphinx или Lucene, и я даже их скачал и немного ковырял. Но начав по старинке с LIKE %%, я постепенно добился того, что мне нужно. Как я уже писал, это не живой полнотекстовый поисковик, отвечающий на вопросы, это скорее тег-поиск, и можно было бы добиться того же результата, просто вручную проставив место для каждого поста. Отбросив у запроса последнею гласную букву (Москва — Московский/Москве/Москву, поэтому поиск по «Москв»), а так же закинув тайтл в 255-символьное поле и сделав по нему индекс, я добился вполне удовлетворительной скорости поиска и полноты выборки. Разумеется, не сразу, по мере увеличения базы и сбора статистики использования и багрепортов (даже сейчас я фиксю по нескольку багов в день, в том числе довольно критичные, пусть и глупые). Особенно много головной боли было из-за группировки постов у блоггеров, зато это во много раз повышает удобство.
А дальше оставалось только собирать базу блогов — с каталогов/рейтингов, просто с поиска, кто-то даже сам добавлял через форму. Сейчас в базе 113 блогов и 23000 постов (за месяц удвоил), правда в силу специфики примерно четверть постов — про Таиланд, про другие страны куда меньше. Причем многие блоги ведутся практически «в стол», у них нет посещаемости или аудитории, хотя есть отличный материал. Но искать их довольно сложно. Но один раз добавив блог, я подписываюсь на все новые посты из RSS, которые добавляются в индекс, что очень удобно. Посты в ридере приводятся в стандартный вид тем же парсером, поэтому нет никакой разницы, полный фид или краткий (при желании я вообще мог бы скачать полностью все посты вместе с фотографиями и показывать их у себя на сайте, но мне это не нужно).
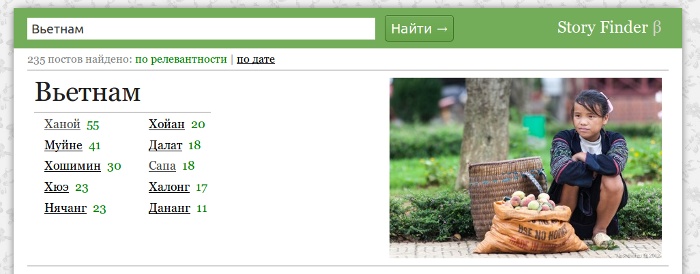
Офигительно удобная вещь, жаль пока только вручную собирается. Выдача по большим странам вообще не имеет смысла
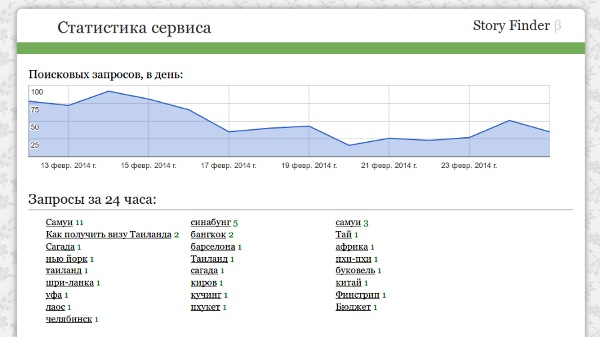
Откуда первые посетители? Ну первой десятке тестеров я присылал ссылку сам, и затем корректировал выявленные недочеты. Когда же сервис стал более-менее работоспособным, я анонсировал его на форуме TravelBloggers (сообщество тревел-блоггеров), что дало 140 посетителей, положительные отзывы, советы и свежие блоги в базе. Со своего паблика в VK со 140 подписчиками я получил еще 75 посетителей (удивлен эффективностью), с твиттера столько же (хотя там самым последним анонсировал), немного с чана и спарка (я даже создал там профиль как «стартап» =). Ну и затем логично ожидаемый постовой на блоге, который принес аж 700 посетителей. В среднем на каждого посетителя 3,8 просмотра, а после спада активности на сайте осталось примерно 20-40 человек в день с закладок. Итого за первые три недели:
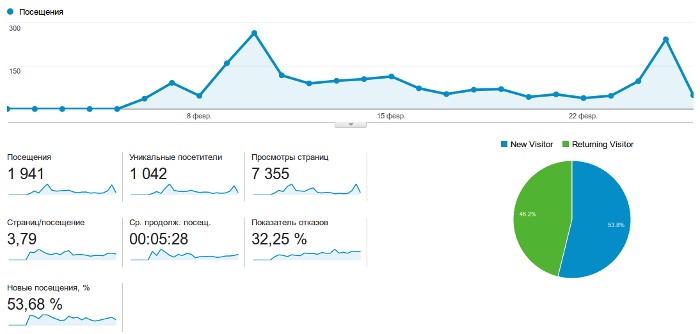
Но число посетителей ничего не значит, если они не пользуются сервисом. Однако с этим так же все в порядке:
1400 поисковых запросов (без меня и только уникальные)
1200 переходов на сайты (по статистике LI, то есть реально на 10-30% больше)
БД весит 600мб, тумбы фотографий — еще 300мб, сам сервис крутится на обычной VPS c 512мб оперативки. Все что светит в веб, написано на CodeIgniter, парсеры — отдельные консольные php-скриты. LA на уровне 0.05, большинство запросов отрабатывается меньше чем за 0.1c
Пока что я вполне доволен темпом развития. Разумеется, я ожидал более взрывного роста, особенно во время старта (на самом деле нет никакой разницы, когда вы наконец запустите проект), блоггеры не особо спешат просто так советовать сервис читателям (кроме разве что DimaX’а и 9seo, но это не те, кого я ожидал). Даже несмотря на появления в источниках трафика у многих. Зато я за это время успел улучшить поиск)
Планы по поводу проекта — разумеется, развивать его. Сейчас три основных направления — увеличивать базу блогов (искать новые, разбираться с проблемными), улучшать поиск (например, недавно сделал штуку для объединения выдачи по нескольким запросам в один, Бирма и Мьянма например), и продвигать сервис. Конечно, совсем на сарафанное радио полагаться нельзя, но первые два пункта куда важнее пока что.
А если смотреть глобально.. Моя цель — миллионная месячная аудитория (о как. Ну или 30к ежедневной, хотя это немного разные вещи). В тревеле такое возможно, да, посмотрите топ LiveInternet в категории Путешествия. Разумеется, обычный поиск по блогам такую аудиторию не соберет, но и поиск в общем-то только вершина айсберга. И даже он вполне может дойти до как минимум тысячной аудитории. Может я себя (и проект) и переоцениваю — тогда это останется просто поисковиком по тревел-блогам, интересным нескольким сотням людей) Как минимум мои проблемы он уже решает, по поводу планируемых поездок в Петчабури или Канчанабури — связка WikiTravel+StoryFinder полностью покрывает мои потребности в информации для путешествий.
Буду рад отзывам и предложениям по улучшению — а особенно адекватным багрепортам и дельным предложениям (а заодно и скриптом-сервисом для автоматизации сбора этого и возможностью оставления анонимных отзывов, вроде реформала, только нормального). Только перечитайте перед этим предназначение сервиса, он не настроен отвечать на запросы вроде «где в Бангкоке посольство Аргентины».
PS. Пока делал сервис, побывал в 4-х странах, 7-и городах и 3-х островах. Кто сказал, что в постоянном путешествии или тропиках нельзя работать?) Был бы интересный проект 😉
Молодец, думаю сервис будет полезен многим. Главное не останавливаться.
Я тебе придумал новый домен — TraBlo.ru, коротко и звучит. 🙂
zxczxczczxczc, не вижу логики. Поясни, что имеешь ввиду.
Ivan, ага)
А, теперь дошло. Нет, спасибо, оставь себе)
если нужно 30к в сутки — то начинаю осваивать отзовы по отелям,базам.санаториям пост-совествким и близ-туристским (египет, турция, марокко. ..)
вообще — чтоб взлетело — нужно нарастить мясо.
а для мяса — и быстрого — только глобал парс по ключам именно в пакет-тревеле.
ну, глубоко имхо конечно.
но с чисто блогами от первого лица — быстро не взлетит.
*тут припомню твой спор с деввером. НЧключи для трафа и потом сайт или сайт а потом ключи)
Охуенно! Уверен, что буду сам пользоваться.
Vlad, увы, ты совершенно не понимаешь сути сервиса и вообще СДЛ) А так же по той ЦА, которая мне интересна. Отзывы про отели в Египте читают пакетники, зачем они мне?
А собирать траф с ПС я вообще еще долго не собираюсь и не рассчитываю на него, так что даже не знаю, что сказать) Не ПС едиными жив интернет. Ну время покажет)
любой пакетник мечтает стать самостоятельным нищебродом)
просто он еще не готов морально.
нужно его подтолкнуть в сторону!
Влад, это же сервис, для сервиса поисковый траф сложно нарыть.
Двигаться нужно в сторону Серфберда — сначала парсить линки, потом часть контента, потом только целые посты,открыть сайт для индексации, а потом выгрести всю рекламу с постов, пересраться с поставщиками контента 🙂
Ну и последнее — продать проект Фейсбуку за 19 миллиардов 🙂
Vlad, отнюдь. Хотел бы, стал бы, а снаружи сколько не подталкивай — толку нет. В любом случае я ни вижу объективного предложения — про Египет я посты соберу, от таких же самостоятельных туристов (они уже есть, просто их довольно мало). И, что дальше? Запихивать выдачу в индекс Яндекса? Каталогизировать все отели и собирать отзывы (это вообще другая категория сервиса)? Нафиг нафиг короче)
Запрос «секс в таиланде» ничего не дал. Беда 🙁 104 поста найдено — релевантность ноль 🙁
Максим, лаконичней надо быть) И как я уже писал, такие запросы задавать поисковику бесполезно, он их не переварит. Запрашивай просто секс, ну или ультимейт ссылка http://storyfinder.ru/?q=blog%3Atourwebring.com+секс
Все-таки сфинкс будет получше. Как по качеству поиска, так и по скорости.
Да и парсеры давно есть универсальные, которые без проблем справляются с версткой любого блога. Будут вопросы — стучи, подскажу.
Отличный сайт, собираюсь в Будву, сайт выдал 54 поста, буду изучать)
Очень хотел увидеть данный пост. Мне, как самому немного умеющему кодить, особенно интересно именно про разработку.
Да, ты хоть не сидишь без дела, сразу выкладываешь свою работу. Я пока не дорос. Перфекционизм, или как там это называется? Хочу сделать сразу все.
Кстати, а что, правда, поиск только однословный какой-то? Я тут для своего движка прикрутил поиск. Сначала тыкался, смотрел решения и ничего путного вообще не попалось. Одно голимое дерьмо: либо простая деревяшка, которая ищет очень плохо, либо перемудренный код с мегабайтами классов, что мне совершенно не нужно. Пришлось опять велосипед писать.
Сделал с использованием Стеммера Портера, а далее просто каждому найденному слову присваиваем вес (если в тайтле, соответственно, больше веса). Ну и дальше уже сортирую по весу.
Получилось вроде неплохо и даже релевантно. Многословные отрабатывают хорошо.
А вообще, надеюсь взлетит проект. Сам уже захожу довольно регулярно с тех пор, как ты ссылку давал.
И да, чан прикрути 🙂 Пусть тревеливеры перемывают косточки, например, Маше и Анджею
aktuba, ага, перейду со временем на сфинкс. По скорости и качеству может лучше, но мне нужна кастомизация) Парсеров — странно, не особо встречал, точнее, по точности они страдают, и опять таки мне нужны кое-какие специфичные вещи (число комментов и фото например), из-за чего проще свой велосипед запилить.
Михаил, угу, хоть там и только 4 точно по теме, остальное просто в тексте)
Ленивый вебмастер, а то я не перфекционист) Просто нужно знать меру, нерабочий проект выкладывать конечно нельзя, но и допиливать всякие мелочи можно без проблем на рабочем проекте (к примеру, на момент запуска двухсловные запросы вообще не работали, а выдача по некоторым словам типа Пая была полна разного мусора).
Ну наиболее шустрый и адекватный — да, однословный. Ну посмотри выдачу по Чианг Маю например) Вполне адекватен, но для многого спотыкается или слишком задумывается. У меня поиск фактически по тайтлу идет, но я изначально не рассматривал многословные вопросы для ответов, это гео-поиск в первую очередь. Ну дык, а как ты тогда многословные находишь? Вес для каждого слова, потом суммируешь, или как?
Угу, взлетает потихоньку) Не, пусть будет только радуга и пони, лол, общение конечно будет, но постараюсь создать более адекватное.
У меня в основном тоже по тайтлам (если найдено мало, то уже по тексту).
Например «Виза из Чианг Мая в Бирму» примет вид «виз чианг бирм» (отбрасываются стоп-слова и <3 букв). Окончания могут быть любыми. За каждое найденное слово, н-р, +3. Если встретились все слова, то присваиваем относительно большой вес (н-р, 25). Сортируем посты по весу.
Я понимаю, что у меня тоже не ахти и по сути деревяшка, но если нужно, могу прислать. Там кода как такого немного (большая часть — функция стеммера). Если поиграться с весами в зависимости от кол-ва слов и что-то еще доделать, может оптимизировать (я ж говнокодер еще тот),то думаю норм будет.
Спрутэ блеать. Ну не любишь ты сео, понятно, я тоже, но нельзя же главную ссылку поста на свой же собственный проект ставить с nofollow, ну ты че?)
«кроме разве что DimaX’а и 9seo»
Я тебя обидел что ли как-то, вообще ссылки не поставил, лол))
«Буду рад отзывам и предложениям по улучшению»
Их есть у меня) Судя по постоянным комментам типа «Запрос “секс в таиланде” ничего не дал. Беда 🙁 104 поста найдено – релевантность ноль :(» и др. я уже на 100% уверен, что тебе не удастся объяснить всем своим юзерам, что у тебя не полноценный поисковик, а «это не живой полнотекстовый поисковик, отвечающий на вопросы, это скорее тег-поиск».
Надо идти другим путем.
1. Организовать все так, чтобы акцентировать внимание юзеров именно на «тегированных» запросах. Для этого, например, на морде или где в навигации на видном месте сделать список самых частозапрашиваемых стран в каком-нибудь виде, а под ними или при наведении или как-то хз еще сделать список самых частых мест в данных странах. По клику на название места, соответственно, делать поиск по q=МЕСТО, тогда поиск твой будет работать ок.
2. Если кто-то сам пишет запрос, не тыкая по предложенным линкам в п.1, то сравнивать его запрос с базой имеющихся мест и стран, ну то есть, если набирает чел «Самуи», то ок, юзаем свой поиск, выдаем результаты. А если чел ищет «Самуи секс», что не совпадает на 100% с предзабитой базой мест, значит, запрос идет «человеческий», а не «теговый», и хочет получить релевантный ответ, то вместо своего движка поиска подключаешь сфинкс или аналогичный полноценный поисковый двиг (или вообще какой-нить кастом гугл серч или яндекс.хмл, если в них можно задавать базу урлов, которой ограничить поиск, если нет, то нах они не нужны, конечно).
И это, подсказка запросов так и не работает, подсказки показываются, но по клику на них не подставляются в строку поиска, чего не уберешь?
Ооо, да, забываю сказать уже давно, нельзя в куки запоминать, по релевантности или по дате показывать посты? Т.е. если я вот выбрал «по дате», то в следующий раз, когда буду юзать сайт, автоматом выдавать «по дате».
Мне кажется с каждым апдейтом сервис становится все более офигенным. Молодец!
Спрут, сделай возможность добавить feed рубрики. Например: есть личный блог + есть отдельная категория по путешествиям. Вот из этой рубрики и тянуть посты. Благо wp позволяет выдавать rss рубрики вида — /feed/?cat=9
Это не я, оно само ( Плагин, с сапы же ссылки толкаю, а так на это внимания не обращаю просто. Исправил.
Просто перебор с числом ссылок в посте, к тому же в предыдущем (и в следующем про Самуи) опять ты будешь, хах.
Ну так как они не получают ответ на свой вопрос, они не будут им больше пользоваться. Можно даже по статистике это отследить.
Да, уже делаю. Типа того, как сейчас запрос «Таиланд» выглядит. Просто я тут подумал, что заодно с базой мест надо еще вбивать географические координаты, чтобы потом можно на карте показывать места/ближайшие, + однозначная связка место — страна. То есть будет еще отдельная страница с картой на всю страницу, где показаны все интересные места.
Интересная мысль. Причем достаточно будет просто все запросы из больше чем 2-х слов обрабатывать так.. Или, опять таки, для запросов из трех и более слов делать запрос не LIKE %секс%таиланд%, а LIKE %секс таиланд%. Хотя нет, там тоже чепуха будет выдаваться, на многословные почти невозможно ответить без разбиения на отдельные слова и подготовки базы… Подумаю еще, но пока таких запросов меньшинство, и результаты сами отваживают от использования его заместо гугла.
Надо убрать или пофиксить, ага.
Форма запоминает (после перехода на дату все последующие запросы тоже сортируются по дате). Хм. Но ведь тебе только по Самуи интересно по дате, а соберешься на Ко Тао — уже по релевантности же нужно, или нет? Впрочем, датой пока пользуется мало кто, можно и повесить куку.
CHE, почти не встречал блоги, у которых посты в этой категории были достаточно хороши. 5-10 мутных постов с фотографий с телефона и несвязным текстом. Поэтому даже и не добавлял особо, хотя в ридер закинуть несложно, как и вытянуть из категории все посты. Тем более часто для каждого блога приходится слегка корректировать парсер, и делать это для блога с 5 постами в категории, когда у меня на очереди стоят десятки блогов с сотнями постов каждый, несколько недальновидно) Форма добавления открыта.
Ленивый вебмастер, хм. То есть взять все тайтлы, исключить предлоги, отбросить окончания, создать таблички id_word|word и id_word|id_post. Для запроса соответственно разбиваем так же все слова, ищем по каждому, мерджим результаты/подсчитываем число совпадений. Хотя лучше не только по тайтлу, но и по тексту, к тому же тут не учитывая, идут ли сова друг за другом. То есть велосипед, который уже давно сделан в сфинксе… Хм. Потом, может быть)
Нет такого понятия у нормальных людей, как «перебор ссылок» 🙂 У сеошников может и есть, а в традиционном СДЛьном понимании интернета — нет. Ставить ссылку незачем, когда очеведно о чем речь, например, с текста «Яндекс», «Википедия» или «кинопоиск», а мой скромный бложек явно в этот ряд не вписывается))
Ну и прекрасно, как говорится, больше ссылок, хороших и естественных)
Так это проблема, разве нет? Зачем себя добровольно лишать существенной части аудитории? Для максимально быстрого и количественного роста, опять же, мне кажется надо окучивать максимальную аудиторию, тем более, что в этом нет какой-то существенной сложности, вроде, подцепить этот сфинкс или аналог, только потраченное время.
Когда соберусь, тогда и соберусь, а может и вообще не соберусь)) А по Самуи периодически смотрю, и чтобы старое не смотреть, сортирую по дате) Хз, в общем, дело хозяйское, опять же)
Отнюдь, когда каждое слово в тексте является ссылкой — его сложно читать. И именно в контексте последних постов твой блог уже является очевидным и понятным без ссылки) На самом деле да, несколько глупо получилось, просто в каждом посты ссылаться и ссылаться на одних и тех же людей несколько бессмысленно, учитывая что следующие посты (итоги и самуи) без ссылки на тебя опять не обойдутся. Перерывчик)
Я придерживаюсь противоположного мнения. Зачем делать «сайт для всех»? Нужно взять сначала какую-то узкую аудиторию/проблему, и решить её до полного просветления посетителей, а уже потом приниматься решать подпроблемы для более широкой аудитории. Сейчас распылятся я не хочу — к примеру, чтобы корректно и полностью отвечать на вопросы, придется еще проиндексировать многочисленные форумы, комментарии к постам, вопросы и ответы, подключить сфинкс, и прочее прочее, что тянет еще на месяц работы как минимум. Куда лучше сконцентрироваться на конкретной проблеме поиска постов по геоместам, и собирать аудитории вокруг этого сервиса, а уже когда все встанет на самотек и дойдет до приемлемого качества (и размера аудитории) — приделывать уже живой поиск, ну или там дублировать функционал каталога гестов, и прочего. Сделав две вещи хреново, получим двух недовольных посетителей.
Именно. Хотя может связать куку+кейворд? Но проще приделать RSS/email-подписку к выдаче по дате
Что у тебя за любовь к перегибам в споре?) Так, конечно да, но в твоем тексте и близко этого нет. Ладно, закрыли тему, в общем, незачем комменты засорять оффтопом)
По-моему, из всего перечисленного реально нужен в данный момент только сфинкс на многословные запросы, ты же видишь, что даже твоя аудитория, которая давно знает и возможно даже шарит в интернет-делах и та задается вопросом почему ответы не релевантны, чего уж говорить о чайниках. Соответственно, один только сфинкс уже даст +++ к юзабельности и релевантности сервиса, форумы и комменты это вторично, имхо.
Только при некорректном использовании сервиса. Когда запрос про Пай выдавал на первых местах папайю — да, это была нерелевантная выдача, и надо было срочно фиксить, а тут я сразу пишу, что поисковик не отвечает на вопросы, и ищет по местам. Что умеющие читать люди и ищут.
Но ведь я с ним не работал, а значит вопрос не просто подключить, а установить, разобраться, расфигачить-нормализовать БД, настроить переиндексацию, интегрировать весь код в текущий, а всё ради 3,5 анонов, которые все равно ищут не ради инфы, а ради теста. Нецелевая трата времени.
А то ты не знаешь, какой я перфекционист) Если уж берешься отвечать на живые вопросы — ты должен находить на них ответы, а без форумов это нереально (ну кроме банальных типа «как получить тайскую визу в Лаосе», а что-то более сложное «на каком сонгтео доехать из Чумпхона до сайри пляжа»).
Мне тоже кажется, что нужно в первую очередь озадачиться поиском. Я понимаю, что сейчас просто по гео. Но ведь многие будут как раз искать определенные темы «Виза в Камбоджу» или «Бордер ран из Паттайи».
О! Как еще одна идея.
Протегировать все посты на основе слов.
По сути и тегов будет не слишком много:
— виза
— виза ран
— бордер
— секс
— что посмотреть
— достопримечательности
— … (статистику подкопишь и увидишь)
Т.е. тегируешь скриптом на основе встречающихся слов в тайтле.
Далее при поиске вычленяешь эти же ключевые слова + гео и подсовываешь пользователю нужные посты.
Если тегов нет, то просто гео.
Думаю, это будет даже лучше и быстрее, чем сфинксы-хуинксы.
Кстати, что чаще всего запрашивают в строке поиска? Отдельные города или конкретные темы?
Ленивый вебмастер, статы открыты, сам глянь http://storyfinder.ru/stat . Отдельные города-места-страны разумеется.
Не будут. Посты ищутся по гео-местам, а не по вопросам. Кому надо — пользуется, кому нужны ответы — в гугл.
А смысл тегировать, если они так в тайтле остаются и поиск по ним же ведется? Не понимать.
Ту скорее надо просто для не гео запросов искать не «виза таиланд», а отдельно виза и отдельно таиланд, а затем объединить по раскидать по весам. Хм, для двухсловных типа Нью Йорк тоже должно сработать…
Ну да, можно не тегировать. Просто первое, что пришло, ну или быстрее искать.
Т.е. если в запрашиваемой фразе есть «фрукты», то ищем по тегу, а не выдергиваем каждый раз из тайтла.
А у тебя гео-места тегированием или как?
Ну и в плане SEO на страницах запроса, типа http://storyfinder.ru/?q=%D1%81%D0%B0%D0%BC%D1%83%D0%B8 неплохо поставить h1 🙂
Чуть посмотрев статьи, можно выделить еще тегов:
— цены на продукты
— как снять дом
— жилье
— интернет
— пляжи
— фото
— как добраться
— парк
В общем, я бы в этом направлении копал.
То фрукты и ищем, зачем заранее тегировать? Тем более придется обеспечивать тегирование всех результатов. Зачем?
SEO не нужно. Результаты выдачи закрыты от индексации.
Теги не нужны =) Человек хочет на панган, он вбивает в поиск панган, первый же результат — про сам остров, внизу список постов «как добраться/жалье/бла-бла-бла». Или эта инфа уже есть в самом посте. К тому же, инфа о том, как добраться, уже есть на викитревел, как и вся прочая в тегах.
Я пока копаю в увеличение базы блогов и релевантности по гео-запросам)
Рекомендую почитать книжку Getting Real
Кстати да, годна книжка, много про итерационную разработку и пользу MVP. Ну и та статья Пола Грэма про прокрастинацию, ссылку на которую я уже скидывал)
Я бы парсил html используя Tidy, а искал бы конечно Sphinx’ом.
Писать набор правил под каждый блог не вариант. Даже если путем накопления они и будут покрывать большую часть потребностей. Смена темы или движка и все 🙁
Такие вещи нужно автоматизировать.
А так ок.
Кстати фавиконка мне напоминает лого Symfony
И что? Посты то уже в базе. Накроется только добавление новых постов из RSS. И то далеко не факт, темы то пишутся по стандартам.
Если бы я собрался индексировать миллионы блогов — безусловно. А так сейчас для новых блогов или вообще ничего править не надо, или пару исключений добавить (мусорная инфы выше текста). Зато почти все анонсы — чистый текст, и для корректного числа фотографий не надо прыгать с бубном, точность на высоте.
Спрутэ, сделай на главной вывод тумбов с ссылками на посты. Можно и плюсовалку добавить.
Замути стартап? Присоединяйся к БМ? =)
Как раз сегодня мне в оффлайне один кадр о них напомнил, восхвалял прямо. И до моей деревни добрались =(
Статистика регистрозависимая… ‘Самуи’ и ‘самуи’ отдельно, не порядок))))
Молоток, желаю серьезного развития проекту. Реально респект по самой идее, хотя и не путешественник, думаю аудитория, которая в теме, оценит на ура.
При наборе запроса всплывает подсказка,но нажав на нее она пропадает и ничего не происходит. Хотя как я понял она по идее по клику на подсказке, она должна запустить поиск.
xekcc, каких именно?
Неандерталец, особенно забавляет, когда они своё МЛМ называют бизнесом)
NONNON, fixed. Хотя это помогало отследить, кто к примеру переходит по по ссылке в подборках мест, кто из подсказок и т.д. Надо уже полноценную мониторилку прикручивать, а то по LI то я отслеживаю, но для оценки качества сайтов нужнее.
Тимур Лишицки, с клавиатуры работает. Да, я в курсе, выше уже писал.
Хорошая работа, поздравляю. Как планируешь монетизировать свой проект?
Андрей кто эти 30 000 в день? Такой оптимизм чем то подкреплен? Твоя ЦА это путешественники, возможно те кто дикарем любит отдыхать, есть проекты нацеленные на эту ЦА с посещаемостью в 30 000 в день?
респект. Но делай поиск )
Александр, ну зайди например в http://www.liveinternet.ru/rating/ru/tourism/month.html , сколько людей посещает форум винского (там же путешественники сидят?), или Туристер. Сейчас самостоятельные путешествия в тренде, с каждым годом поток увеличивается, и не только пакетникам в Таиланд, но и зимовщиками, и дикарями. 30к я конечно одним поиском и анонсом в блогах не наберу, это понятно.
Миха, как посещаемость подрастет, буду думать. Точечно билеты, реклы по направлениям (аренда домов на Самуи, гид в Праге), РСЯ наконец.
[weber], угу)
Андрей, я думаю там в основном поисковый трафик, они же генерируют большое кол-во контента, или твоя идея в том чтобы объединить вокруг поиска сообщество путешественников, чтобы они генерировали контент?
Александр, а что думать, зайди в статистику да посмотри (гостевой пасс у него 111 вроде, на странице рекламы можно посмотреть), у форума винского 100к посетителей в день (600к просмотров), 12к ядра («закладочники», которые регулярно сами посещают сайт), 60к — да, с ПС. Причем 3к посетителей — из Таиланда. И за три года аудитория удвоилась.
Зачем? К чему всё это собственничество, «пишите контент для нашего сайта»? Куда эффективней с авторами-блоггерами сотрудничать, давая им читателей, а не заставлять их писать только для себя. Моя идея в том, чтобы люди сразу искали тревел-запросы у меня, а не в Яндексе, а не в том, чтобы собирать весь траф из ПС по гео-запросам.
Блог awd кстати проиндексировал, офигительный охват (хотя и пришлось повозится с картинкам из форумной галереии), теперь кроме Тёмы будет еще кто-то в местах типа Уругвая/Монтевидео/Кении и т.д.
Может уже кто-то писал, но все комменты прочесть не осилил: подвисался на RSS СториФайдер, а в нем ссылки (полный пост) стоят не на твой ридер, а на источники — мне кажется, лучше сделать на СториФайндер, там выводить полный пост и в конце — ссылку на источник.
А иначе смыла транслировать в свой RSS чужие анонсы я не вижу.
Спрут, ты когда берешься рассуждать о сео или сдл, вспоминается South Park, 10й сезон, эпизод №2 — «Smug Alert».
Не пожалей 20 минут, посмотри, поймешь, о чем я. Серьезно. Не пожалеешь. Хорошая серия с хорошим сюжетом.
Антон, и подвергнуться анафеме от всех блоггеров? Или тебе никто не говорил, что воровать чужой контент нехорошо? Да, техническая возможность есть, и в ридере, и в выдаче, отправлять посетителей на внутреннюю страницу с постом, с нормальным дизайном-шрифтами и без рекламы, без перехода на другой сайт. Сам догадайся, чем это обернется от авторов контента. А так я занимаюсь распределяю заинтересованных людей по блогам.
онаним, не стесняйся, все свои, выражай свои мысли. Али тямы не хватает? В этом посте я всего лишь рассказал о том, над чем работаю и почему, и не сказал ни слова ни про сео, ни про СДЛ. И даже не стал пафосно кричать «вот это я называю СДЛ» (так как это очевидно). И да, от недостатка ЧСВ/тщеславия я не страдаю.
Есть что сказать — говори прямо.
Хм, не понял насчет живых запросов. Ну вот сел я сейчас фигачить этот самый умный поиск, реализовал поиск сначала по отдельным словам, а потом мердж только совпадающих. Получилось круто, только всякие случайные запросы отбросились, и где раньше было 100 результатов, стало 5. Плюс куча головняка с логикой, как например реализовывать «виза AND (таиланд OR тайланд)» я уже без поллитры разобраться не могу, это надо опять архитектуру пересобирать чтобы тасовать так запросы.
Но не суть. Сравнил «новую» выдачу и старую… И ничего! Если ответа нет — то его нет. Если есть — топ одинаковый. Если отбросить мусорные слова (предлоги), то выдача идентичная. То есть вот нафига я сейчас насчет этого парился вообще? Говорил же, что без форумов будет хрень, а так надо просто очищать запрос от слов-паразитов, и будет ответ. Просто это иногда критично («Пи Пи» например отбросилось бы из-за длины), так что проще научить вводить правильные запросы, с чем 90% посетителей успешно справляются.
вот и случай советы называется..
Крутой сервис. Делай сразу версию на английском под большую аудиторию. Будет круто.
Обязательно. Только не сразу, я на два фронта не смогу работать)
Спрут, ты ли это? В титле не хватает окончания «…и как я его продал Яндексу за 100500 мульёнов рублёв» )) Без обид, но твой сайт — просто обычный интерфейс к БД (про непростой пусть разработки собственного поисковика — особенно повеселило) с простейшим парсером html, настоящим поисковиком его назвать сложно, не позорься епт) Использование Sphinx в данном случае это не поиск легких путей, а совсем наоборот. Возможно ты просто не разобрался что там к чему?)
Raoul, ну с академической точки зрения у меня, разумеется, не поисковик, а хер на палочке, я с этим совершенно согласен. Но с практической точки зрения он делает как раз то, что мне нужно (там еще конечно целый вагон доработок в очереди, но в целом он уже вполне юзабелен), и пост я писал именно о практическом подходе к созданию сервиса, а не академической реализации алгоритма, работающего с заданной точностью, и индексирующий по полрунета в день (и интересный только 3,5 профессорам). И для сервиса, к тому же, на первое место встает уже полнота и качество базы, а так же наглядность результатов, а не абсолютная точность (к тому, ну вот как сфинкс реализует релевантность? Число встречающихся слов? Тьфу. Только поведенческое, хотя и она часто сбоит).
Сфинкс — поставил, начал читать how to на хабре, в итоге подумал нуегонах, LIKE работает как надо и ОК (но ты же не думаешь, что результаты я сортирую так, как мне mysql их выдал, да?). Когда упрусь лбом недостатки текущей реализации поиска, буду допиливать, а сейчас это не нужно.
Заметь, опять таки, я не пишу, что это офигенно сложно, и я тут решаю всегалактическую проблему инноваций. Я просто столкнулся с определенной проблемой, и попытался её решить так, как умею (пару лет назад я бы просто не смог его создать от недостатка скилла).
Давай следующий заголовок «Как я делал StoryFinder и заработал миллион» 🙂
Ага, а потом я проснулся..)
Не, следующий пост надо будет написать про то, как я зафейлил буржуйский развлекательный сайт. Для контраста)
ты не потянешь. такое должно висеть на хорошем сервере и поддерживаться командой людей
О, жопоголики подтягиваются, с 60-му то комменту) Ну сейчас впска вполне справляется и имеет солидный запас прочности, и с разработкой я тоже как-то один вполне успешно справляюсь. Как потребуется — начну расширяться. Но, учитывая используемый оборот «такое должно», что либо объяснять логикой бесполезно)
Вывод тумбов интересных постов за день или неделю. На matadornetwork.com над шапкой есть что-то похожее.
Не посмотрел South Park? А ты посмотри, посмотри, может чего увидишь интересного.
Тяма? Не нужна в интернете тяма, в интернете любой унылый человек — герой. Например, ты человек унылый, и по совместительству герой, спорящий со всеми по любому поводу, устраивающий споры ради споров. Это надутое эго.
онаним, и? Рад за тебя, но какое отношение это имеет к этому посту? В интернете любой унылый человек — еще более унылый. Если не хватает ума IRL, то в интернете его не прибавится.
Да, споры я люблю. В спорах рождается истина. А вот унылых ватников вроде тебя — нет.
Годный сервис, однако допиливать нужно. Взять хотя бы запрос http://storyfinder.ru/?q=барокай : вот вам и нерелевантные барокамеры )). Думаю, обрезание слов до последней гласной — не совсем удачная идея. А в остальном — однозначно зачет.
alexxlab, как ни странно, поисковик ище места только по правильному названию. Самые популярные опечатки я еще исправляю (тайланд на таиланд например, если только одно слово), но вот следить за всеми — увольте. Проще бить словарем)
Есть более лучшее решение, не включающее в себя морфологический анализ и семантический ад с дополнительными таблицаами всех слов и словоформ, при этом работающий так же эффективно?
Хм.. Действительно Боракай. Однако очень уж распространенная ошибка. Признаю свою неправоту. Желаю удачи с сервисом ).
По поводу лучшего решения стоит копать в сторону нечёткого сравнения строк, IMHO.
Спрутэ, ты куда больше времени убил на написание костылей к тому что у тебя есть и хрен знает сколько времени убьешь на это, чем если бы ты изначально разобрался в Sphinx.
Смотри в сторону Sphinxql http://sphinxsearch.com/docs/manual-2.1.6.html#sphinxql-reference — обычные SQL запросы, для php даже модулей никаких ставить не надо, пример:
public function getAllQuantity() {
$sql = «SELECT 1 AS temp, COUNT(*) AS num FROM » . self::INDEX_NAME . » GROUP BY temp»;
$result = $this->sphinxConnection->query($sql);
$row = $result->fetch_assoc();
return number_format($row[‘num’], 0, ‘.’, ‘,’);
}
Настроить переиндексацию? У тебя нет миллиардов записей, так что тебе даже не надо заморачиваться с частичной переиндексацией (а это кстати тоже легко настраивается). На твоей базе можно делать полную переиндексацию раз в час, займет это меньше минуты. Настройка? 1 строчка в крон.
Boris, ОК, поднять легко, как мне к примеру настроить релевантность, чтобы посты с бОльшим числом комментов и фото были выше? Сколько раз там встречается в тексте, разницы нет.
Сейчас у меня главная проблема не найти все посты (LIKE справляется после напильника), а именно отсортировать их, а конкретно — четко знать, есть ли слово в тайтле или нет, и в какой оно форме (пай != папайя). Точнее нет, слово легко, а вот словосочетание — уже косяк. Сейчас слегка нормализую слова и в запросе, и в тайтле, а там уже array_intersect и на основе числа совпадений. Это немного улучшило выдачу, но повторюсь — у меня не стоит цели искать сложные запросу по всему тексту всех постов, запрягаясь морфологией, это скорее для двухсловных геоназваний, хотя сейчас остались косяки (например, поиск «Чианг Май» теперь не включает «Чиангмайский», что нехорошо, хоть и не критично). Жаль я не догадался еще и категории-теги парсить..
Делаешь в таблице несколько колонок например num_photos, num_comments, сортируешь по ним. Подключаешься к Sphinx из консоли mysql -P9306 -h127.0.0.1 и тестишь, запрос будет типа такого (проверял на своем)
select * from index_name where match(‘me.com’) order by num_photos desc limit 10;
Насчет «большинство запросов отрабатывается меньше чем за 0.1c», о которых ты пишешь. Уж не знаю как ты тестировал, у меня на рандомных запросах типа http://storyfinder.ru/?q=%D1%81%D0%B8%D1%8B%D0%B2%D0%B0%D0%BF%D0%B0%D0%BF%D1%84%D0%BA%D0%B2%D1%8B%D0%B0 страница открывается от 3 до 17 секунд (сама страница, без графики/css и прочего).
Boris, кривенько. Я сейчас 5-7 параметров использую, и вручную ползунки двигаю для подстройки. Можно конечно их объединить в один общий «rank», а затем сортировать по нему… Но наличие кея в тайтле есть важный параметр (с ним и без него rank в три раза отличается), а его не забиндишь в поле. То есть опять костыли на костылях будут, либо полнотекстовый шустрый, но нерелевантный, либо неполнотекстовый шустрый и релевантный. Нет, наверное можно и там как-то это настроить, и привести к удобовариемым результатам, и я безусловно этим займусь, когда постов будет 100-200к. А пока меня устраивает мой велосипед. Ну разве что факультативно отправлять все запросы >1 слова в сфинкс, как советовали выше.
Именно, на рандом запросах он скатывается в поиск по тексту, что разумеется занимает прорву времени, и чем больше растет база — тем дольше запрос. Зайди в статистику и посмотри, сколько времени загружаются популярные запросы (ну кроме очевидно фейловых на естественном языке) — Самуи 0.3с, Бали 0.16с и т.д. (сейчас чуть увеличилось, видимо очистка регулярками знаком препинания из всех тайтлов чуть лагает, Таиланд уже 2с). Потому что поиск идет по оптимизированным и коротким тайтлам. Там в комментах в коде есть время исполнения php-скрипта.
В Опере белый бэкграунд у инпута не отображается.
http://ge.tt/8L74OFR1/v/0
Валидацию поля ввода нормальную добавь — запрос ‘—‘ приводит к пустой странице,
запрос ‘1 or 0’ вешает сайт (ну или это так совпало)
А я просто добавил свой блог) И я так понимаю — он на модерации. Мне идея нравится, буду следить как развивается данный проект.
Сделай виджет для WP настраиваемый, что бы можно было его поставить на другие сайты — думаю их с удовольствием разместят те кто в твоей базе — ну к примеру я указываю слово «прага» и генерится код виджета где отображаются 5 новых отзывов — я бы с удовольствием разместил — идеально было бы что б можно настроить отображение в фрейме на своем сайте или переход на сайт-донор — но это мелочи ……. второй вариант — это тот же виджет с отображаемыми отзывами к примеру по слову «прага» и ниже их ОКОШКО ПОИСКА, что бы можно было набрать и посмотреть другие города.
Андрей!
выдели хоть как нибудь строчку ПОИСКА на storyfinder а то даже опытному пользователю очень трудно понять где поле ввода для поиска на этой зеленой перетяжке
Увидел очень интересную СТАТИСТИКУ на storyfinder за 11 мая 5500 посетителей? т.е. это половина всех посетителей за 30 дней случилось 11 мая. КАК И ПОЧЕМУ это произошло — опыт может быть полезен всем
А как попасть в рейтинг «живых блогов»?) У меня сайт вроде живой, но не отображается в этом списке(
Дружище, а не подскажишь, почему мой блог не участвует в поиске и рейтинге? Добавлял уже давно, написано — блог есть в базе, после модерации появится…
Спасибо.
Денис Демидов, привет, добавил.
Aliel, рейтинг живых блогов формируется по статистике за последние 30 дней. Если вас там нет — значит вы не входите в топ20 блогов по активности.
——
И да, пожалуйста, по всем вопросам касательно StoryFinder лучше писать в ветку обсуждений http://storyfinder.ru/disqus или напрямую на почту. Я не кусаюсь, а комменты не лучший способ сообщить мне о проблемах на сервисе.
Ну и комментарий от человека, вообщееееееее далекого от программирования и прочих штук! Только что не от блондинки)) Андрей, поздравляю с успешно стартовавшим проектом! Это — супер работа. Когда первый раз увидела Стори Файндер (увидела его из статистики, так как были с него переходы на наш сайт), мне он сразу понравился. Я — просто пользователь, на которых данный сервер и рассчитан. И когда узнала, что над его созданием трудился ВСЕГО ОДИН человек… Это впечатлило. Почитала комментарии к этой статье — в общем, собаки лают, а караван идет)))
Эх, в скобочках имя тайскими буковками не отображается..)
А что нужно сделать, чтобы попасть в рейтинг стори финдера? Я там сделала, как сказано, но пока ничего не происходит.
Спасибо!
Может есть уже готовые поисковые системы которые ищут по списку доменов, на основе их выдачи сделать свою выдачу.
….
…
есть конечно — называется это чудо яхопайпс — можете добавить ЛЮБЫЕ сайты и выдрать с них любые куски текста или кода — но конечно надо разбираться … я делаю по другому … нахожу на сервисе простенький ГОТОВЫЙ вариант «грабилки» и клонирую на свой аккаунт в яхо а потом уже перенастраиваю под себя… на выходе вы получите готовый rss поток в нужном вам формате с автоматическим обновлением .. штука мега крутая … вот примеры популярных пайпсов http://pipes.yahoo.com/pipes/pipes.popular — выбиаете понрившийся а затем жмете на кнопку View Source и видите КАК ВСЁ УСТРОЕНО — можете клонировать к себе на аккаунт в яхо но сразу скажу что акк в яхо зарегить ОЧЕНЬ муторно но это того стоит (при регистрации почту рекомендую gmail указывать что бы потом легче было подтверждать). К сожалению людей разбирающихся в этой теме в русскоязычном сегменте ОЧЕНЬ МАЛО(вернее они есть — но кто разобрался сразу начинают работать с буржуйским траффиком и «теряются» ну как пример был такой блогер «tormoz» — чуток разобрался и кудато пропал,сайт свой он продал но материалы кой какие там остались http://brokenbrake.biz/category/Yahoo-Pipes/ ) . Почитать для начала можно и то что гугл даст >> http://vk.cc/3iLAD0
так же немного ликбеза по яхопайпс есть здесь http://www.arserblog.com/yahoo-pipes-faq-97/
Константин, есть, но во первых они не позволяют в должной степени кастомизировать выдачу, а так же управлять ранжированием.
leo, для 210 блогов для каждого добавлять правила? Во вторых, если я не ошибаюсь, пайпсы изначально созданы для манипулирования фидами. Там есть функционал индексирования сайтов целиком? Функционал RSS-аггрегатора блогов делается как два пальца, хоть на пайпах, хоть на php, нужен поиск. В третьих, сбор инфы — только часть задачи. Нужно её как то ранжировать, и выдавать в удобочитаемом виде. Это уже куда сложнее. В четвертых, это зависимость от стороннего сервиса, как и в случае с использованием google custom search.
К сожалению, просто протыкав пайпы, нормальных поисковик сделать не получится. Разве что группировать новые посты в блогах по городам/странам/регионам, и то придется попотеть.
Интересный сервис.
Через поисковик такую инфу сложно искать.
А здесь все, как в топсапе, — в одном месте.
Мне кажется он будет востребован и не только среди независимых путешественников — люди любят читать истории.
А что такое странное название storyfinder, а не travelstories или что-то подобное?
С таким названием нет четкого позиционирования.
Мобильное приложение под него будешь делать?
/Спрутэ, сделай на главной вывод тумбов с ссылками на посты. Можно и плюсовалку добавить.
Ага — было бы лучше, как на смартлабе
Еще хорошо бы добавить возможность подписываться на определенных блогеров, а в мобильном приложении приходило бы пуш сообщение, если этот блогер публиковал новый пост.